 报表设计规范
报表设计规范
# 一、SQL性能优化规范
经常使用,必须遵守
简介:本章为编者在项目中常用优化策略。针对本章的内容,需要掌握以下能力:
(1)了解数据库运算时基础的内存、硬盘交互,
(2)了解数据表扫描,基于对扫描的理解来提升SQL执行效率,
(3)了解执行计划,掌握到这一层级可以满足90%项目的需求。
基本理念
当我们执行SQL查询语句时,数据库的操作是先根据SQL语句从硬盘中获取数据,然后加载进内存中进行后续计算。由于SQL语句有执行的先后顺序,因此当SQL一开始查询的数据量越小,加载进内存时间越短,并且整个SQL执行也越快。
# 1、明确字段,不取多余
解释:只取我们需要的字段,不用的不取。不要随意用“*”来查询全部。例如:
假设A表总共有10个字段,只需要用到其中两个字段,那么查询语句中只取我们需要的两个字段,速度比查询所有字段的速度快。
# 2、大表关联,先做过滤
解释:大表关联查询语句中,做到先过滤再关联。不允许使用WHERE来进行关联。提前过滤好,在硬盘和内存交互上、内存计算上可以节省很多时间。
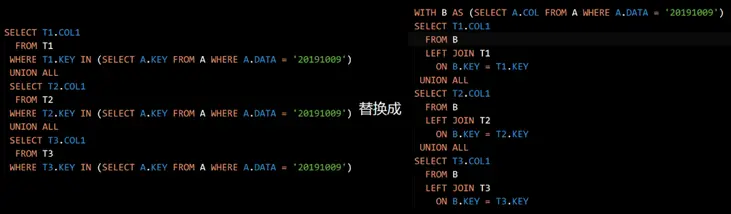
# 3、提取共性、减少重复
解释:SQL语句中有多处重复的子查询,可以将其提取出来,进行参数化,减少数据库查询次数。
# 4、减少不必要的扫描计算
解释:如果UNION ALL可满足要求,就使用UNION ALL,而不用UNION,因为UNION会有一个比较然后去重的过程,而UNION ALL没有。
# 5、经常查询的大数据量表,需要创建索引,过滤和排序尽量放在索引列上操作
解释:索引会提高SELECT效率,但是会影响到INSERT及UPDATE的效率。索引的介绍及创建方式等内容不在此赘述。
# 6、区间范围比较(特别是索引列比较)要有明确边界,降低比较时的计算精度
解释:用>=、<=代替>、<,。在取值区间±0.00001(或者其他足够小的值)即可实现代替,例如:
(1)数值比较,A>1替换成A>=1.00001
(2)时间比较,A>2019-09-01 00:00:00替换成A>=2019-09-01 00:00:00+0.0001
(3)日期比较,A>2019-09-01替换成A>=2019-09-02
如果不做替换,数据库计算A>1时,可能会一直计算到A>1.000000000000才能得出A>1的结论,这是浪费计算时间。
# 7、避免显式转换、隐式转换导致索引失效
解释:避免数据库运算时对索引列进行转换,例如:
(1)显示转换举例,假设索引列为日期型数据,和字符串型日期比较。
错误写法:TO_CHAR(T.索引列,'YYYYMMDD')>='20190715',
这里是用函数将索引列由日期类型转换为字符串类型,导致索引失效。
正确写法:T.索引列 >=TO_DATE('20190715',’YYYY-MM-DD’)
(2)隐式转换举例,假设索引列是一串字符串型的数字,取索引列值为1的数据。
错误写法:T.索引列=1
这里是数据库用隐式转换将索引由字符串类型转换成数值类型,导致索引失效。
正确写法:T.索引列=’1’
# 8、大表查询时,避免子查询中的排序计算,排序需放在执行计划最后一步
解释:尽量在子查询中避免ORDER BY、DISTINCT等语句。其中ORDER BY是对结果进行排序,而DISTINCT和GROUP BY是在计算过程中排序。子查询数据量较大时用EXISTS子句代替DISTINCT。
# 9、决策报表中,尽量将多个数据集合并为同一个数据集,减少并发数量
解释:一个数据集就是一个并发,数据集过多导致并发过高,数据库加载压力大,计算效率会降低。可以用以下方案减少决策报表中的数据集数量:
(1)将A、B、C三个指标的每月/每日的趋势,以年月/年月日为条件进行关联,而不是每个指标单独一个数据集。
(2)查询结果为一条记录的数据集,直接关联在一起,例如三个数据集A、B、C都返回一条记录,那么可以如下图进行数据集合并处理。
注意
报表中控件的数据字典如果数据量过大,并且涉及到控件联动,此时将一个数据集拆开成多个数据集可以提高控件加载效率,与本条规则相违背,需要酌情考虑。
# 10、不常使用的,参考建议
- 使用表连接替代EXIST
- 使用 WHERE 过滤替代 HAVING
- 对于复合索引,WHERE子句中必须包含索引的第一列才一定能够使用到索引
- 可对索引列使用LIKE ’xxx%’,避免对索引列使用 LIKE ’%xxx%’,’%xxx’
- 索引列计算尽量避免对索引列使用IN、OR等,可以考虑用UNION ALL代替
# 11、高阶优化
# 分区分表
解释:将一个表分成若干部分,减少单次扫描的数据量,提升效率,例如将五六年的数据按年分表存储,单次查询只扫描一年的数据,但是跨年分析会有影响;
# 数据压缩
解释:即做数据预处理,先定期在数据库里计算好,然后报表中直接取结果数据来展示,例如将每分每秒的数据汇总成一天一条记录,这种就是做数仓/数据集市;
# 硬件提速
解释:即用GP、HANA等高性能数据库,提高数据运算速度。
# 二、报表开发环境规范
# 1、开发环境规范
Jar包环境:本地设计器的Jar包与远程设计的工程,Jar包版本一致
插件一致:本地设计器的插件与远程设计的工程,插件版本一致
原因:避免Jar及插件版本不一致导致的各种无效、假保存等问题远程设计:项目及模板开发过程,在保证Jar及插件一致前提下,尽量远程设计
每次在dev环境开发,修改,内部测试通过后,发布到UAT环境供业务人员测试,关键用户UAT测试通过后,再发布到生产环境,供最终用户使用。
# 2、过程控制规范
# 权限控制
协同开发过程中,注意分配账号及权限,开启报表角色权限控制
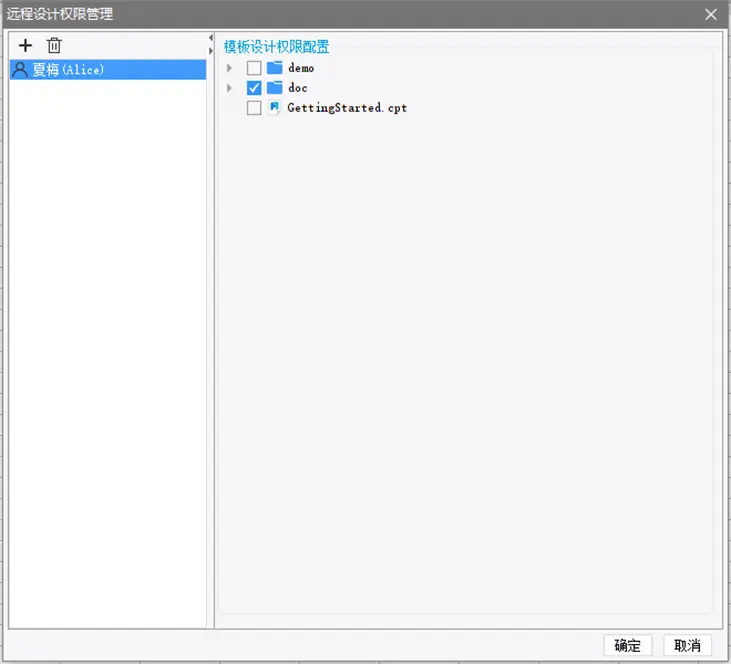
项目上多个开发人员的,使用远程设计权限控制。使用10.0的远程设计权限控制比8.0使用更方便。
# 一致性
# 协同开发or模块开发过程中,需保证UI风格相对一致
原因:避免返工或显得不专业
1、配色可以使用设计器的预定义配色去控制。

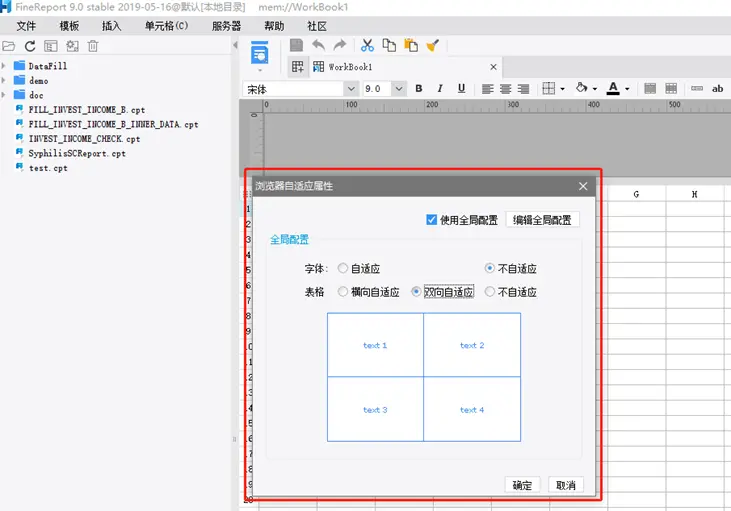
2、大量决策报表的项目,必须考虑模板自适应配置,统一使用全局配置
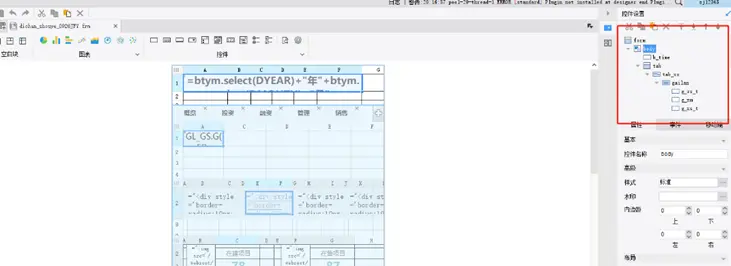
# 协同开发or模块开发过程中,报表中有多个组件,控件时,需保证组件命名的一致性,规范性
# 3、备份策略
手动备份整个工程文件,或者在决策平台开启自动备份或者手动备份
以下以linux环境为例:在开发的时候,在开发环境、UAT环境开启自动备份,讲备份的目录选在工程目录之外,然后通过shell脚本将备份文件move到其他服务器或者其他目录,避免大量的备份文件导致应用过大,以及一台服务器出故障导致工程损坏。
备份目录选在工程之外的路径

实例:定时备份oracle,删除历史文件,并将备份转移到另外一台服务器
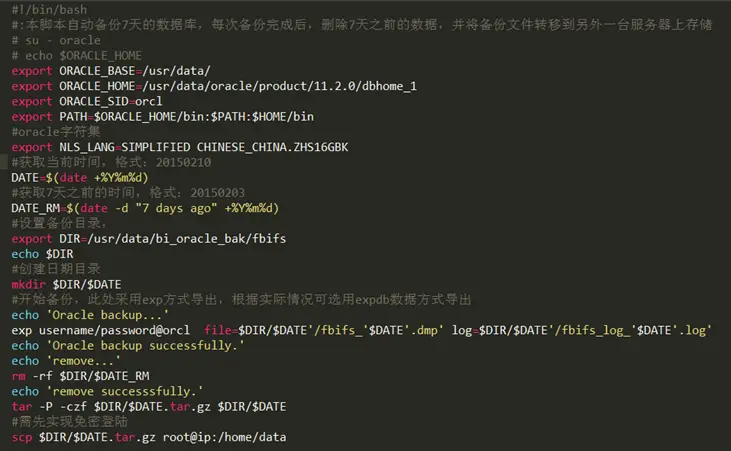
# 4、备份修改
- 优先在开发环境调整、验证与测试
- 如果没有开发环境,必须先模板备份(名称可以加上日期后缀,比如***.cpt_V20190627),基于备份的模板做修改调整,不影响正式使用
- 模板调整修改需记录在案,方便追踪(V10.0支持在设计功能追加版本备注)
# 三、报表命名规范
# 1、目录命名规则
必须执行
不使用中文,名称整体由26个字母、数字、下划线组成,首位必须为字母
目录名需做到见名知意,与业务模块相关。例如财务: FINANCE、人事: HR、营销:MARKET
下层目录用下层目录可以用‘_’来分隔命名,例如营销的销售部分:MARKET_SALE;营销的回款部分:MARKET_GETIN
(建议执行)
报表目录层级尽量不要超过四层
可以独立一个测试模块TEST,给各实施人员或运维人员预留自己开发测试空间TEST_NAME,模板一旦正式启用必须另存到正式模块目录中
# 2、模板命名规则
必须执行
模块目录名+下划线+编号 例如MARKET_SALE_001
编号可以按照制作顺序递增,不可重复
准备一张类似下方的报表映射excel,可以放在文件管理系统中,根据开发情况及时更新。

# 3、数据集命名规则
必须执行
参数面板数据集:以para_开头,例如地区选择下拉框的数据集para_area
数据字典数据集:以dic_开头,例如产品映射字典数据集dic_product
报表主体数据集:以report_开头,例如客户销售数据report_customerSaleData
图表数据集:以chart_开头,例如产品占比图表chart_productRatio
# 4、参数命名规则
必须执行
全局参数:以g开头,例如gSaleGroup,gProduct,gPerson
模板参数:以p开头,例如pDate,pCurrency,pUnit
数据集参数:以s开头,例如sCompany,sProject
# 5、条件属性命名规则
推荐执行
可以允许简短的中文命名,方便业务和开发
格式 哪种条件属性_实现什么功能,例如:宽度_projguid列隐藏
# 6、超链接命名规则
推荐执行
可以允许简短的中文命名,方便业务和开发
格式 哪种超链接_实现什么功能,例如:网络报表_跳转到明细
# 四、功能实现方法规范
- 常见需求的实现方法规范,在满足功能的前提下,以性能、便于维护为目标。
- pc端报表(预览、分析、填报)、大屏、移动端,特殊功能的实现方法规范。
# 1、展示报表制作
必须执行
1.图块多的报表(如驾驶舱、大屏)使用frm开发,一般来说使用自适应布局,每个图块一个组件,无特殊要求不要使用组件叠加
2.减少前端过滤的使用,尽量在数据集中过滤
3.报表不要使用隐藏行、列,如有需要使用条件属性隐藏
4.公式中也要注意格式,如嵌套公式应做到每个公式换行,每个条件或结果换行
5.大屏模板制作,用外置图片,否则非常影响性能,可以使用外置图片插件比较方便,但是自适应插入方式有bug,还没更新
建议执行
1.减少跨组件获取单元格值使用
2.控件数据字典数据量大且重复数据多时,使用专用数据集
3.如非必要,不要在公式和JS中使用SQL函数
# 2、填报报表制作
必须执行
1.大数据量填报报表要尽量读写分离,查询报表和填报报表分离
2.填报报表设置参数,新增导入时不展现数据,查询修改时尽可能添加过滤控件,减少查询结果集
3.业务主键字段通常设置不可修改,如必须修改则应用数据库表中代理主键UUID字段做填报主键,新增数据时公式赋值新的UUID
4.没有导入需求时,尽可能在单元格做即时校验,有导入需求时则应将所有校验设置在提交校验中
建议执行
1.安装excel导入逻辑插件,默认按标题再位置匹配的逻辑
# 3、参数开发
必须执行
1.统一采用英文命名方式:
采用26个英文字母和0-9这十个自然数,加上下划线_组成,共36个字符,不出现其他字符。采用英文单词或英文短语(包括缩写)作为名称,参照字典表给出的基础命名,没有的去翻译,不使用无意义的字符或汉语拼音。
2.大屏中设置参数要考虑到不同报表块参数加载速度的问题,避免一个大屏模块过多的不同参数
3.参数大小写一致,建议都用大写,不要用汉语命名
4.多个数据集中的同一个参数默认值设置成相同,产品的尿性,有时会出现影响
5.避免数据集参数和模板参数使用同一参数名
6.避免参数名称和fr系统参数重名,避免混淆
建议执行
1.涉及到不同TAB模块的同样指标的参数,参数名建议带上对应TAB模块的名称,以地区参数为例,例如:TAB1DIQU,TAB2DIQU
2.对于多个模板都要使用的参数,可以设置成服务器参数,供多个模板使用
# 4、条件属性
必须执行
1.设置条件属性时候需要考虑到性能问题,一行上面一个条件属性能解决的问题不要用多个条件属性
2.尽量合并多个条件属性为一个,通过多写条件判断实现,条件属性过多降低前段展示速度
3.隐藏行列一定不要直接隐藏行列!通过条件属性设置行高or列宽=0达到隐藏行列,方便维护
建议执行
1.条件属性根据实际需求命名,不要用默认的“条件属性1”“条件属性2”
2.要考虑性能问题,能不使用条件属性则不使用
# 5、防宕机
必须执行
1.必须迁移内置数据库(finedb/logdb)调整迁移后连接的连接池数量,尽量调整日志输出级别输出较少日志,不用日志统计可以关闭输出到数据库
2.sql查询不要太复杂,太多全部扫描导致给数据库带来太大压力,导致数据库执行缓慢,从而反馈到应用无响应
3.在测试环境做模板,确保不做出笛卡儿积模板预览导致系统宕机
4.windows下使用tomcat等容器,正式运行环境请后台运行,不要使用带黑窗的tomcat等,后台运行尽可能使用最小日志输出(非调试情况)和按时间分割日志文件
5.所有工程的连接池数量总和不可以超过数据库允许的值
6.配置web容器的最大线程数量略低于模板业务数据连接连接池的数量
7.尽可能避开填报笛卡儿积问题
8.linux上要用nohup 启动工程 防止被 shell注销干扰,后台运行尽可能使用最小日志输出(非调试情况)和按时间分割日志文件
9.vm内存不要超过32g,尽量不要超过系统物理内存的1/2,内存大于10g的时候尽量使用GC回收器
10.在linux上修改应用最大打开文件数(默认1024,至少i调整到6w+)在遇到客户使用附件,或者缓存到磁盘的功能的时候会产生影响
11.表单的背景不要重复设置,尽量不要用大的图片做背景,实在需要可以用css+web图片处理表单背景
建议执行
1.限制数据集的结果集在任何参数情况下都不可以查出大量数据,最优sql结果<100 ,最大最好尽量不要超过1w
2.服务器尽量不要跑其他任何东西,纯净运行报表服务,如果运行有其他东西,尽量设置XMS=XMX
3.尽量避免使用toImage函数,能用webimage就用webimage
4.安装防宕机插件,限制sql行数,目前不建议使用自动排队回收功能
5.使用数据字典的时候,尽量使用专用数据集(就两个字段最好),而不是拿完整的select*的数据集
6.配置一排同一个父格的时候尽量设置成所有格子使用一个父格而不是依次继承
# 五、报表UI设计规范
在FR报表的开发过程中,对于报表的UI,需要注意字体、格式、配色这几方面。具体实施,不同客户会有不同需求,但是应保持风格一致的中心思想,如,标题都是黑体,正文都是宋体等;配色风格,如都是暗色系,则不应突然冒出个亮色系。
中心思想
首先,如果客户有自己的UI设计规范,那应以客户的设计规范为准,满足客户满意度是第一要务。
其次,若客户没有自己的UI设计规范,那在报表的开发过程中,应遵循本UI设计规范。
然后,UI设计规范这块,不同的人有不同的看法,核心是,风格一致。在此基础上,字体、格式、配色,可因地制宜,根据实际情况处理。 举例:财务的报表,要求字段都左对齐,那应当遵循其既有规则。
必做规范
1、风格一致,整齐清爽。
2、字体方面,有些商用收费的字体应该避免使用,如微软雅黑等。
以上两点是必须执行的。
# 1、字体
中文字体里,**最安全的就是宋体、仿宋、黑体、楷体、隶书、幼圆。**另外,思源黑体、思源宋体、庞门正道标题体、文泉驿系列、站酷系列,以及方正的楷体、黑体、仿宋、书宋,都可以免费商用。
无论是明细表的标题还是图表的标题,建议加粗,且字号大于正文。
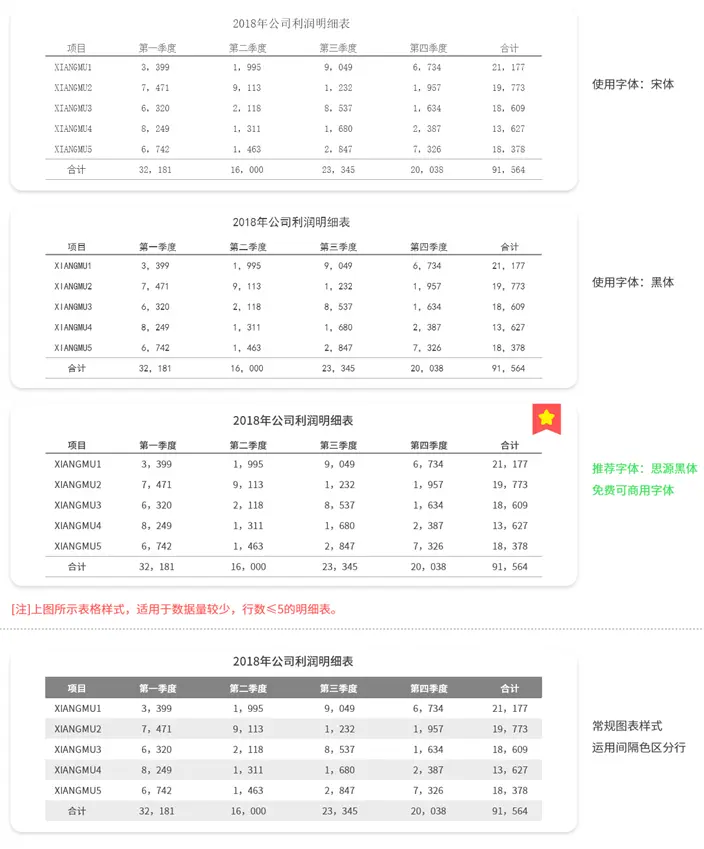
明细表:
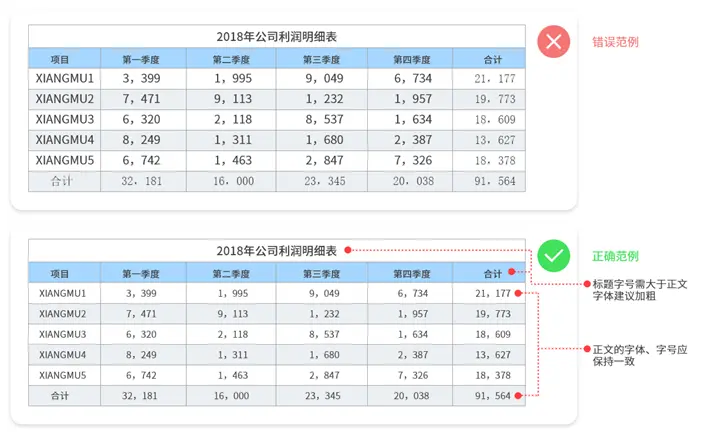
不同报表的标题,字体、字号应一致。若出现表头,或是二级标题,字体应小于主标题,大于正文,建议加粗;正文,字体、字号应一致。
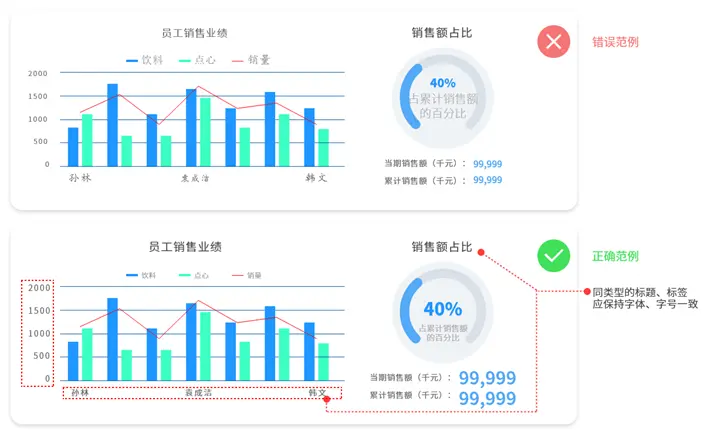
图表:
图表中涉及文字的地方有标题、标签、轴标签、提示。这四类,同类应保持字体、字号一致。标题字号一般大于其他三类。建议这四类,字体一致,后三类字号一致。
# 2、格式
所有标题居中;数字的小数位一致。
明细表:
明细文字,格式统一,都居左或居中。
明细表第一行、第一列空出来,留出点余白。行高最好一致,自动换行不建议开,字数不一致的情况下,会导致行高不一,显得很乱。
网格线方面,保持风格一致即可,即线型、颜色一致。
此外,明细表的行列不许直接隐藏,用条件属性实现。
图表:
标题居中。坐标轴标题,若有,如Y轴标题,则位置应保持一致,都居上或居中。
标签的位置,至少同一类图表,如柱形图,应保持一致,都在外侧或是内侧。
# 3、配色
明细表:
字体颜色一般都是黑色,特殊情况,如数值预警高亮,因地制宜。
表头加背景色,不建议大红大紫那些过于鲜艳的颜色,建议蓝色或灰色等。表头字色根据背景色调整,建议白色、灰色等。
明细表还建议设置奇偶行的间隔色,以达到好区分不同行的目的。颜色同样不可过于鲜艳,建议灰色或淡蓝色等。
配色参考(来自视觉小姐姐的贡献)

图表:
根据背景颜色来设置标题等字体颜色,如图表都是暗色系,那文字的颜色建议白色这样的亮色系。
不同系列色,应遵循美观、舒适的原则,颜色不可太亮太刺眼,要让人看得舒服。
大屏的背景色建议暗色系,因为白色在大屏上的展示效果不好。